Published May 6 2025 · Devina Jain Note: This blog post is created as part of the final project for Center for AI Safety — AI Safety & Ethics Course
Road-map: How shaky benchmarks inspired BCR → 10 rubric criteria → DIY vs Lab table → Automated pipeline → MMLU case-study → What the field should do next.
1 The Problem—Great Models, Fragile Benchmarks
When GPT-4 hit 86 % on MMLU, that was immediately trumpeted “college-level AI.” A few months later Claude 3 edged past at 90 %—but was that real progress or statistical noise?
Benchmarks have become the “north star” guiding research, policy, and deployment. Yet many crumble under a comma swap or domain shift. If evals are all we need, we need to ensure that the evals themselves are trustworthy.
2 Origin Story—From AV Safety to Language-Model Scores
As a self-driving systems engineer at Cruise, I designed a confidence rubric for autonomous-vehicle simulations: a checklist that decided whether virtual test miles actually predicted on-road safety. The parallels to LLM evaluation are uncanny:
Huge test space, never exhaustive
Simulation/artificial tasks stand in for reality
Coverage and representativeness constantly questioned
Safety-critical stakes if evaluation is wrong
So I ported the idea. Weeks of literature review, AISES group discussions, and perturbation experiments became the Benchmark Confidence Rubric (BCR)—a 10-point “credit rating” for benchmarks.
3 The BCR—Ten Criteria, 0 – 3 Points Each
* Thresholds are starting points—need to be tuned with more experimentation and are expected to be domain-specific.
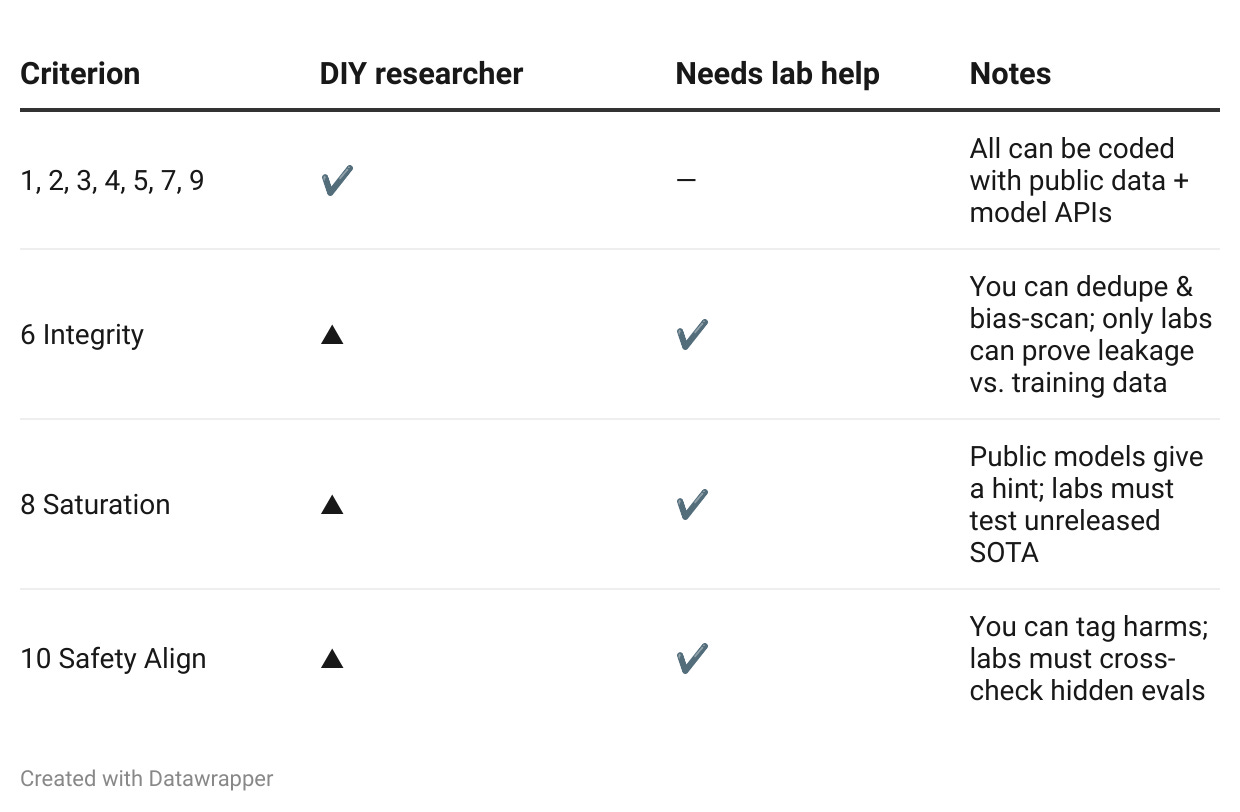
DIY vs Lab-Required (who can score what?)
(▲ = partial score possible; mark “N/A – lab required” to avoid false zeros.)
4 Automated Pipeline—Seven DIY Metrics in Practice
I chose MMLU as a testbed because it is public, broad (57 subjects), and uniform. I also chose to evaluate GPT 4.1 since it’s shown unprecented performance across benchmarks. However as the rubric evolves, it should be general purpose, applicable across benchmarks and models.
Statistical Power: Bootstrap 1000× on GPT-4.1 predictions (zero manual work).
Robustness: Generate three perturbation suites—paraphrase, surface-noise, distractor-shuffle—then re-evaluate.
Coverage: Compute H/Hₘₐₓ entropy across subjects.
External Validity: Compare STEM vs. non-STEM slices.
(Implementation details & code in repo: https://github.com/sofasogood/benchmark_confidence)
Note that this pipeline has preliminary, light-weight, easy-to-prototype implementations of the proposed concepts and are expected to be greatly refined and generalized over time.
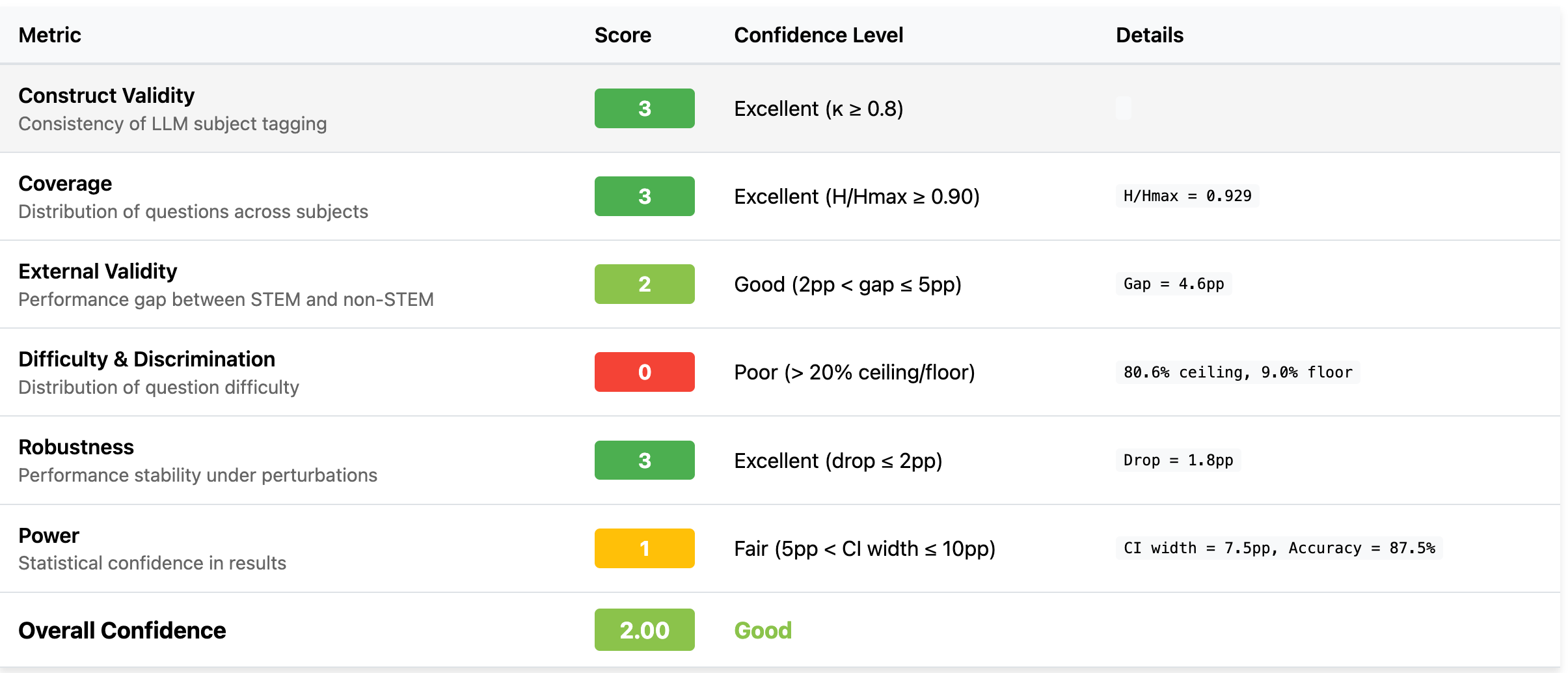
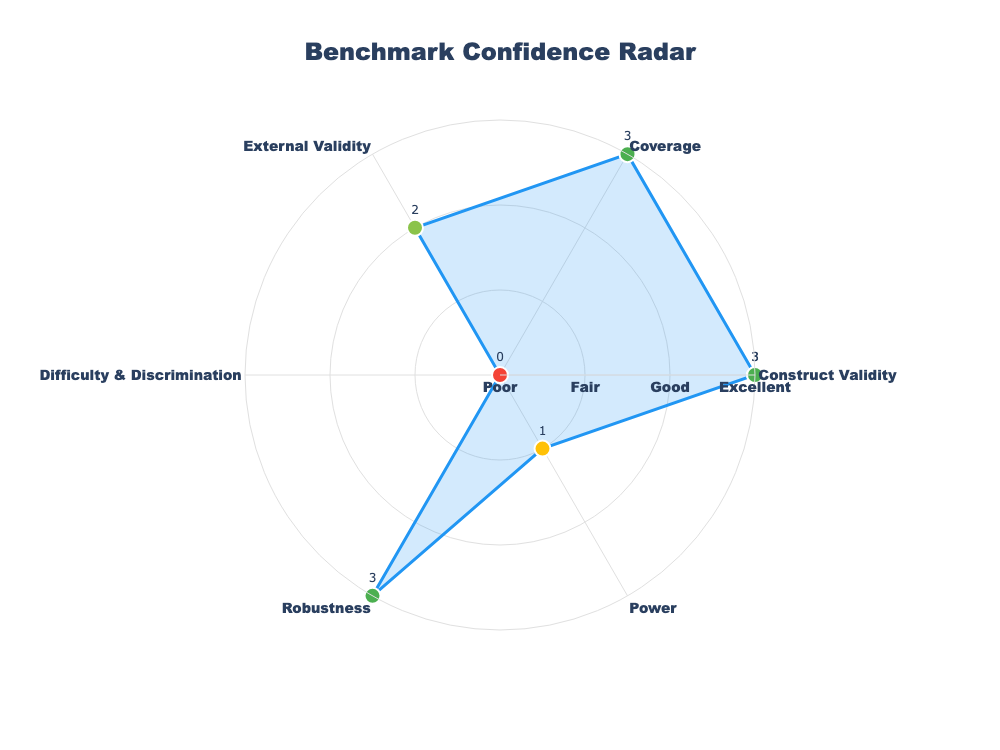
5 Findings—MMLU’s BCR Scorecard
Note: n=300 randomly sampled questions from MMLU
Key take-aways
Construct validity is a bright spot. Automated subject tagging is highly consistent (κ ≈ 0.8). A small human audit could confirm a definitive 3 / 3.
Breadth is not the bottleneck. Subject coverage looks stellar even in a 300-item slice; expanding to the full benchmark is unlikely to uncover big holes here and it’s better to go deeper (more difficult questions).
Ranking capability is the weakest link. With 80 % of items hitting the ceiling, this mini-MMLU version can’t meaningfully separate strong models. Expect even sharper ceiling effects when high-end models see the full set.
Robustness is a pleasant surprise - but keep an eye on scale. A ≤ 2 pp drop after perturbations is excellent, yet we’ve only stress-tested 300 items. Larger runs (or more aggressive perturbations) may reveal hidden brittleness.
Statistical power is still shaky. A 7.5 pp confidence interval means a headline jump from 87 % → 90 % could be pure noise. At least an order-of-magnitude more examples are needed to nail this down.
External validity looks decent but not rock-solid. A 4–5 pp STEM vs. non-STEM gap won’t sink the benchmark, but if that gap widens on the full corpus there is a need for domain balancing or slice reporting.
Caveat: These findings come from a convenience sample of roughly 300 questions (~2 % of the benchmark). Treat them as directional signals, not final verdicts. The full-dataset run may shift individual scores by ±1 and will tighten the power estimate.
🚀 Opportunity: Power-Slices for Rapid Iteration
Most teams run the entire benchmark or randomly sample non-statistically-significant every time—slow, costly, and often unnecessary. Because BCR highlights which items actually carry signal, you can spin up a “power-slice”:
Same statistical confidence, one-tenth the runtime.
Balanced coverage (entropy within ≈ 0.05 of the full set).
No ceiling items, so strong models can still be ranked.
Why you should care: A 300-to-500-item power-slice can finish in minutes, letting you try five model tweaks in a single afternoon and reserve full-set runs for weekly or pre-release gates.
How to spin one up
Filter out items that everyone aces or misses (ceiling/floor).
Stratify so the subject-entropy mirrors the full benchmark.
Size the slice until BCR’s Power metric shows CI ≤ 2 pp for the accuracy band you target.
Freeze the slice for daily experiments; re-compute quarterly as models improve.
Think of it as a high-leverage “unit test” set, with the full benchmark as your final integration test.
🌅 So Where Do We Go From Here?
🛠️ BCR Working Group (open to contributors)
• Tune thresholds — re-run on multiple different benchmarks and models; adjust cut-offs. • Expand the perturbation library - add typo noise, negation flips, flipping characters. • Build an edge-case test-suite every new scorer must pass before merge. • Standardise the code by integrating BCR into the Inspect-AI library.
🔬 Researchers — quick wins
• Run the low-hanging fruit first:Statistical Power + Robustness (usually < 1 hour). • Publish the BCR line item with every new model result - 95 % on a 1.0 / 3 benchmark is a flashing red light. • Patch your weakest dimension before the next big model sweep.
🏢 Labs — internal automation
• Release hashed leakage stats for public datasets (no raw corpora exposed). • Check head-room with unreleased frontier models → return a “saturated / not-saturated” flag. • Tag each item with your harm taxonomy so the Safety-Alignment scorer can run.
🏛️ Conferences & Leaderboards
• Show colour-coded confidence badges 🟢🟡🔴 beside each leaderboard row. • Track BCR drift over time - benchmarks age, falling scores should trigger alerts.•
The next steps involve hardening the rubric itself-tightening thresholds, enriching perturbations, and wiring in lab-only checks-so that by 2026 a BCR score is an established eval of benchmarks Please reach out if you’re interested in learning more or collaborating!
Let’s stop guessing whether benchmarks are solid-let’s measure it.
9 References
Reuel, A., Hardy, A. F., Smith, C., Lamparth, M., Hardy, M., & Kochenderfer, M. J. (2024, November 20). BetterBench: Assessing AI Benchmarks, Uncovering Issues, and Establishing Best Practices. arXiv. https://doi.org/10.48550/arXiv.2411.12990
Salaudeen, O., Reuel, A., Ahmed, A., Bedi, S., Robertson, Z., Sundar, S., Domingue, B., Wang, A., & Koyejo, S. (2025, May 13). Measurement to Meaning: A Validity-Centered Framework for AI Evaluation. arXiv. https://doi.org/10.48550/arXiv.2505.10573
Eriksson, M., Purificato, E., Noroozian, A., Vinagre, J., Chaslot, G., Gómez, E., & Fernández-Llorca, D. (2025, February 10). Can We Trust AI Benchmarks? An Interdisciplinary Review of Current Issues in AI Evaluation. arXiv. https://doi.org/10.48550/arXiv.2502.06559
UK AI Safety Institute, Arcadia Impact, & Vector Institute. (2025). Inspect Evals: Community-Contributed LLM Evaluations [Website]. Retrieved May 30, 2025, from https://ukgovernmentbeis.github.io/inspect_evals/